Efficient Distributed Deep Learning
The Cornucopia project focuses on improving the resource utilization and job response time for distributed deep learning—an emerging datacenter workload. Our work explores the promise of model-specific training speedup, combining both systems and machine learning optimizations. Our current work includes more informed neural architecture searches, and distributed training performance characterization and modeling (ICAC’19, ICDCS’20, and Google Blog Interview).
Managing Compromises in the Enterprise
To minimize risk to the OS and other accounts on a system, organizations often limit their users to the minimal privileges needed on the system. To limit threat propagation within the network, organizations use firewalls and virtual LANs (VLANs) to group hosts into smaller risk pools. They then use monitoring tools, such as intrusion-detection systems (IDS), at the network boundaries between groups to detect threats.
Unfortunately, these enforcement and monitoring tools lack visibility into hosts and other parts of the network, hindering their ability to make informed decisions. Specifically, 1) they are blind to activity among grouped hosts (e.g., within VLANs or subnets), 2) they are blind to the host-level cause (or catalyst) of the network traffic when making security decisions, 3) they can only examine a subset of the network’s traffic without seeing network-wide behavior, 4) they allow adversaries to perform reconnaissance on the organization’s network and infrastructure, and 5) they use broad rules to allow or deny traffic without the ability to consider details.
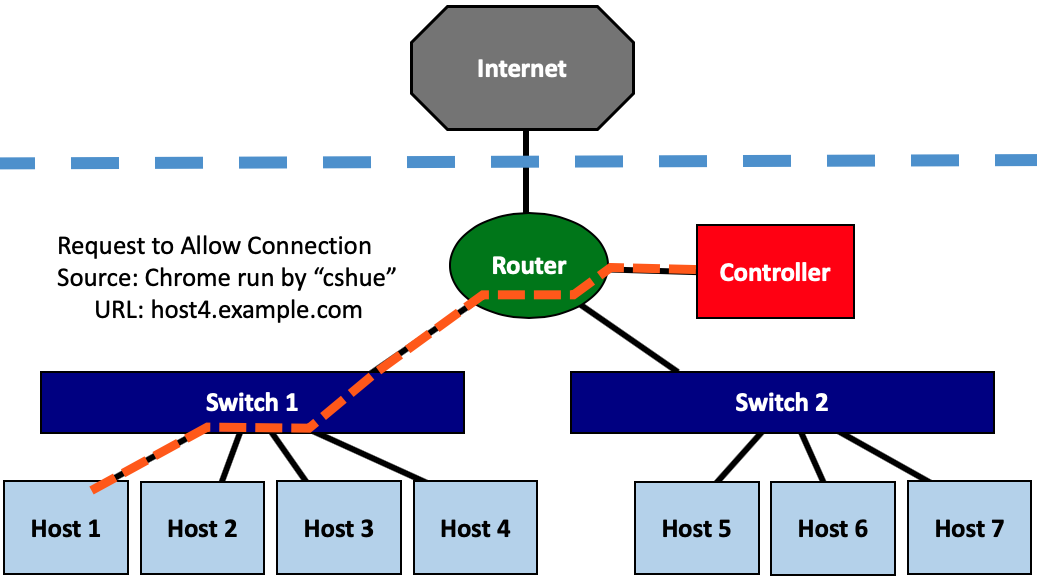
This work seeks to create centralized access control systems for all network traffic and to inform the network access controller of the host-level context and catalyst of network traffic.
Embedded Systems Security
Embedded systems form the core of critical infrastructure, perform auxiliary processing on mobile phones, and permeate homes as smart devices. Yet, embedded software security lags behind traditional desktop security. While myriad defenses exist for general-purpose systems (e.g., desktops and servers), embedded systems present several unique challenges for software security such as greater hardware diversity, limited resources (e.g. memory and power), and lack of support for common abstractions like virtual memory.
Our work in this area includes defenses for protecting embedded software from control-flow hijacking attacks (Recfish and Silhouette); FPGA architectures that balance the throughput and resource requirements of AES (Drab-Locus); and techniques for generating secure random numbers (Erhard-RNG).
DNN Model Execution Caching
The Ripcord project proposes a new infrastructure for improving the performance of deep learning model serving. Our work explores the promise of model execution caching as a means for improving the performance of cloud-based deep inference serving. Model execution caching requires a CDN-like shared infrastructure designed for workloads that see requests for a large and diverse set of models. That is, a workload where the aggregate volume of requests is high but no single model is popular enough to merit a dedicated server.
We present our vision of model execution caching in the context of a hypothetical system (EdgeServe) and the unique challenges and opportunities (DIDL19, Perseus).
Efficient Mobile Deep Inference
An ever-increasing number of mobile applications are leveraging deep learning models to provide novel and useful features, such as real-time language translation and object recognition. However, current mobile inference paradigm requires application developers to statically trade-off between inference accuracy and inference speed during development time. As a result, mobile user experience is negatively impact given dynamic inference scenarios and heterogeneous device capacity. The MODI project proposes new research in designing and implementing a mobile-aware deep inference platform that combines innovations in both algorithm and system optimizations.
Our work presents the mobile deep inference vision (MODI) motivated by empirical measurements (on-device vs. cloud inference and performance characterizations); runtime model selection algorithms that balance inference speed and accuracy (ModiPick); and multi-tenancy GPU inference (Perseus).

Outsourcing Residential Security
While the software-defined networking (SDN) paradigm has had a significant impact on enterprise networks, in particular in data centers, it has not spread to residential users. But, the fundamental properties of SDNs, namely the outsourcing of management and control, are key enablers of a shift in how we manage residential networks.
In our research, we have modified the TP-LINK TL-WR1043ND v2 wireless router with a custom OpenWRT firmware image that enables OpenFlow support. We then created an OpenFlow controller in the Amazon EC2 cloud and configured the router to elevate traffic to the cloud controller. In our research, we confirmed that the latency overheads inherent in the approach would be acceptable in practice.
This research project will study the data collected from multiple residential routers to evaluate the feasibility of OpenFlow. The approach will also examine the feasibility of selectively proxying traffic through VMs in EC2 to enable IDS and protocol-aware firewalling techniques.
When complete, we expect to have results showing the viability of cloud-based network defenses for residential networks directly via cloud computing providers or through third-party services running in cloud environments.
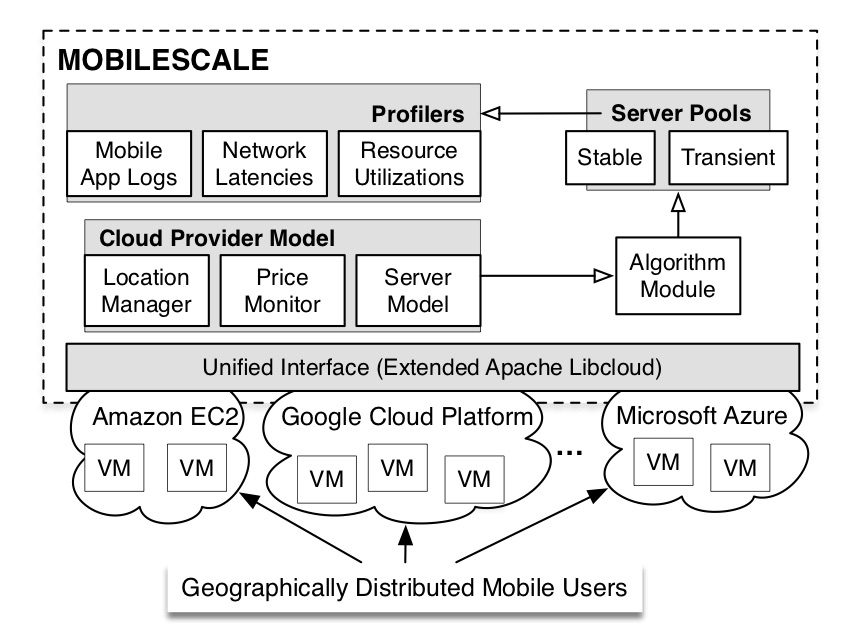
Mobile-aware Cloud Resource Management
Modern mobile applications are increasingly relying on cloud data centers to provide both compute and storage capabilities. To guarantee performance for cloud customers, cloud platforms usually provide dynamic provisioning approaches to adjusting resources, in order to meet the demand of fluctuating workload. Modern mobile workload, however, exhibits three key distinct characteristics, i.e., new type of spatial fluctuation, shorter time scale of fluctuation, and more frequent fluctuation, that make current provisioning approaches less effective. The MOBILESCALE project proposes new research on resource management for mobile workload that differs significantly from traditional cloud workload.
Our work in this area includes harnessing cheaper yet revocable transient resources (CloudCoaster and transient distributed training); and pooling together resources from multiple cloud providers (multi-cloud resources).
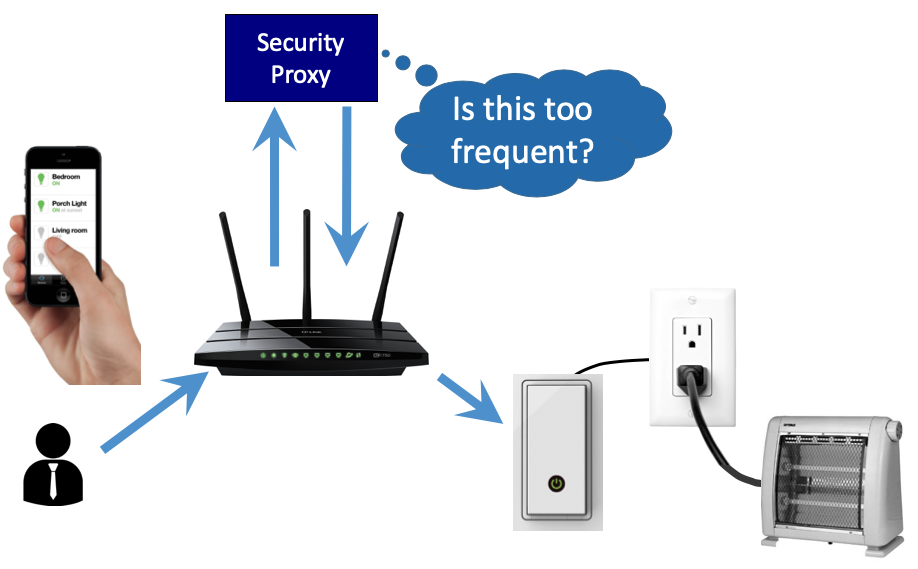
Confidential and Private Deep Learning on End-user Devices
Providing users with control over their personal data, while still allowing them to benefit from the utility of deep learning, is one of the key challenges of contemporary computer science. Our work on the Capr-DL project is focused on performing deep learning operations directly on a personal device, with a trusted framework, allowing both users to retain control over their private data and companies to retain control over their proprietary models.
Our work in this area starts with leveraging model partitioning to circumvent the severe resource constraints of the trusted framework (confidential deep learning and user-controlled privacy and confidentiality).
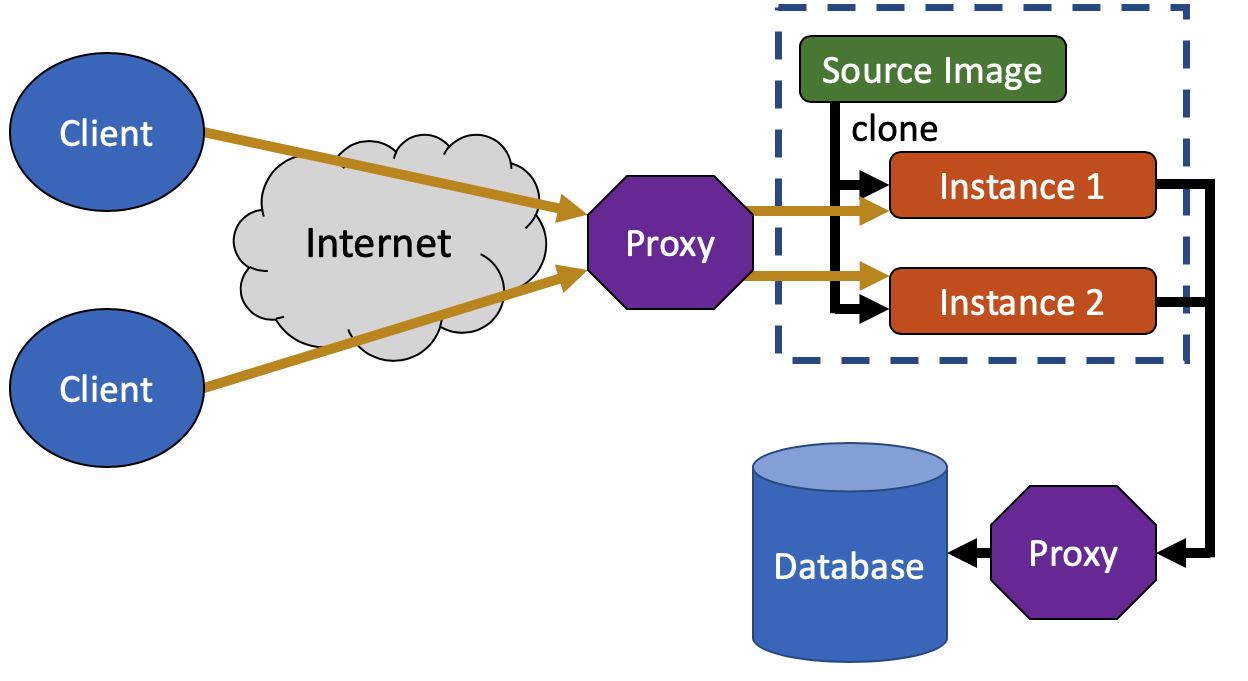
Single-Use Servers
Public-facing front-end servers, like web servers for e-commerce companies or universities, often use shared infrastructure and software in order to support thousands of users. Unfortunately, this shared infrastructure provides an opportunity for attackers: a malicious client can find a vulnerability in the server’s software and exploit it to attack other users and to implant malicious software that will attack future visitors.
These front-end servers often have highly elevated privileges in order to serve a variety of users, from customers, to merchants, to the employees that administer the site itself. But, since it is exceedingly difficult to write defect-free code, these same servers often have vulnerabilities that can be exploited by an attacker. The attackers can thus manipulate these servers into using their elevated privileges for malicious purposes, which is known as a “confused deputy” attack.
In our research, we seek to eliminate confused deputy attacks and the ability for a malicious client to affect others. We do so by eliminating the shared infrastructure associated with these public-facing servers. Rather than provide a single server that many clients use, we create a unique, single-use server for each client. While such an approach would be infeasible with physical infrastructure and prohibitively costly even with virtual machines, we can use lightweight containerization technology to isolate each instance of a public-facing server. When a client ends its session, we simply discard the container, eliminating the ability for an attacker to implant code that will affect future users. Finally, the single-use technique allows us to customize the permissions associated with each container, avoiding the need for highly-elevated privileges that enable the confused deputy attack.
When complete, we expect to have results showing the viability of a single-use server approach even for high-volume public-facing servers. We also will demonstrate how existing application servers can be inserted into such a system with minimal changes.
Marco Polo: Using Wireless Signals to Locate an IP Address
We have developed an approach that can quickly geolocate Internet users that are connected through a WiFi network. To do so, we send specially-crafted signals to the user’s IP address. When these signals are broadcast by the user’s wireless router to the user’s wireless device, they have a discernible signature. We then use other geolocation efforts to scope the Internet user’s location (e.g., to the appropriate city or section of a city). We then drive through the search area listening on wireless channels for the discernible wireless signature. Once we find it, we use directional antennas and triangulation to exactly locate the user.
Our work in this area was published at USENIX WOOT (PDF).
Choreographer: Orchestrating a Moving Target Defense
There are many deployed approaches for blocking unwanted traffic, either once it reaches the recipient’s network, or closer to its point of origin. One of these schemes is based on the notion of traffic carrying capabilities that grant access to a network and/or end host. However, leveraging capabilities results in added complexity and additional steps in the communication process: Before communication starts a remote host must be vetted and given a capability to use in the subsequent communication. In this paper, we propose a lightweight mechanism that turns the answers provided by DNS name resolution—which Internet communication broadly depends on anyway—into capabilities. While not achieving an ideal capability system, we show the mechanism can be built from commodity technology and is therefore a pragmatic way to gain some of the key benefits of capabilities without requiring new infrastructure
The Choreographer project has been explored by the scientific community, resulting in two peer reviewed publications. The first, published in the ACM SIGCOMM Computer and Communication Review (PDF), describes the idea of a DNS capabilities system. The second, published in the ACM/IEEE Transactions on Internet Technology (PDF), describes how DNS resolvers can be profiled to determine whether access should be granted.
Data-Free Model Extraction
Are you under the impression that adversaries can’t steal your model because it is hard to get access to training data for the niche task your model solves? In our latest work on Data-Free Model Extraction we show that adversaries can steal your model with ZERO knowledge of your training data, in a black-box setting where you only expose model predictions to the public. We use a synthetic data generator that maximizes the disparity in the predictions of the victim and the stolen copy (L1 loss) via weak gradient approximation using forward differences. While our work does pose a threat to MLaaS, it poses a bigger threat to on-device ML systems — where attackers can typically make an unrestricted number of queries at no additional cost.